
How Slippage Attribution Reveals What Actually Changed
Slippage attribution describes how a systematic engine separates the total cost of a fill into its underlying causes. A single slippage number says the trade cost more than expected. Slippage attribution, by contrast, says why. Furthermore, it tells the engine whether the cause was structural, behavioural, or accidental. For institutional infrastructure, that distinction decides whether the system continues, adjusts, or halts. As such, slippage without attribution is only a warning. Slippage attribution turns the warning into a diagnosis the engine can act on.
Most retail frameworks treat slippage as a single number to minimise. By contrast, systematic infrastructure treats it as a composite signal to read. A clean attribution turns drift into measurable, addressable behaviour rather than a vague complaint. In this way, the engine learns from each fill rather than just paying for it.
This article examines slippage attribution as an infrastructure and integrity property. In particular, it covers what attribution separates, why raw slippage misleads, how engineers build a pipeline, and how disciplined systems use the read. The approach stays behaviour-first throughout. Structure comes first, and prediction never enters the design.
What Slippage Attribution Actually Means
Slippage is the gap between the price a system expected and the price it received. It is a one-dimensional number on its own. However, the reasons behind that gap are not one-dimensional at all. The engine therefore decomposes the gap into pieces, each of which has its own behaviour. Moreover, each piece can be tracked independently over time.
Slippage as a number, attribution as a story
A slippage number on its own is a complaint. It tells the engine that something cost more than planned. However, it does not say whether the cause was a thin order book, a routing miss, or a delayed signal.
Attribution turns that complaint into a story. It assigns each unit of slippage to a specific cause. As such, the engine can stop asking why a fill was bad and start measuring exactly which part of the system explained it. Furthermore, the story is repeatable, which means it can be tested against future fills.
In practice, this changes the conversation between engineers and the system. Instead of debating intuitions about a noisy day, the team reads the same decomposed components. As a result, disagreements move from opinion to evidence, and decisions become much easier to defend later.
What slippage attribution separates
Slippage attribution separates four basic components for most systematic engines. The first is market impact, the cost of the fill moving the price itself. Next comes liquidity drift, the gap between expected depth and the depth actually present. Routing variance is the third component, the cost of choosing one venue rather than another. Finally, timing variance captures the cost of acting a few milliseconds later than planned.
Each component has its own driver. Therefore, each one calls for a different response. By contrast, lumping them together gives the engine no actionable signal.
The behavioural read inside slippage attribution
Slippage attribution is not a clean accounting exercise. It is a behavioural read on the execution layer. A widening market-impact component means the engine is starting to move the market more than it used to. A widening liquidity-drift component means the venue is changing under it.
As a result, each component carries a different message about the system’s behaviour. The engine reads those messages together rather than reacting to a single total. In practice, this is what turns slippage from a complaint into an infrastructure signal.
Moreover, the behavioural read makes the engine self-describing. A team can hand the attribution output to an external reviewer, and the system explains itself. Therefore, attribution becomes part of how the system communicates, not only how it measures.
Why Slippage Without Attribution Is Misleading
A single slippage number, on its own, tells the engine very little. It can rise for many different reasons, and the response to each reason is different. Therefore, acting on the total alone is almost always a mistake. The engine needs the decomposition before it changes anything.
Why raw slippage hides the cause
A rising slippage number can come from many sources. Liquidity may have thinned. The engine may have started trading larger size. A venue may have changed its order book behaviour. Without attribution, the engine cannot tell which.
Consequently, any response based on the total alone is a guess. The system may slow down when the real problem is venue mix. As such, raw slippage without a decomposition often punishes the wrong layer of the system.
In addition, an undiagnosed slippage rise tends to compound. If the wrong layer is adjusted first, the actual cause stays untreated and continues to widen. Therefore, the cost of skipping attribution is not just bad reporting. It is slower correction when correction matters most.
A widening number with no diagnosis
A widening slippage number with no diagnosis is the worst kind of signal. It says something is wrong. However, it offers no path forward.
In practice, a team facing that signal will either over-react or under-react. Over-reaction shrinks size unnecessarily and starves the system of capacity. Under-reaction lets a real structural issue grow until it forces a halt. Both outcomes come from the same gap, the absence of attribution.
The Components of Slippage Attribution
A useful slippage attribution framework decomposes the total into named components. Each component is measurable. Each one can be tracked across regimes. As such, the engine knows not only what changed, but where.
Market impact as one component
Market impact is the cost the engine’s own order imposes on the price. It is largest when size grows relative to available depth. Therefore, it is the first component to inspect when slippage rises after a size change.
Furthermore, market impact has its own baseline by instrument and regime. A clean attribution compares actual impact against that baseline. As a result, the engine knows whether a fill is unusually expensive for its size, or simply expensive in absolute terms.
In practice, this component is the one most affected by the engine’s own behaviour. If the engine grows size faster than depth supports, market impact widens first. Therefore, watching this component is also a way of watching the system’s own discipline.
Liquidity drift as a slippage attribution input
Liquidity drift captures how depth changed between the time of the decision and the time of the fill. It can widen quickly during news events or session boundaries. By contrast, in calm conditions it stays close to zero.
Inside slippage attribution, liquidity drift is one of the most informative components. It says little about the engine itself and a lot about the venue. As such, a rise in this component points outward, at the market structure, rather than inward, at the system’s behaviour.
Moreover, liquidity drift connects directly to risk policy. When this component widens for several sessions, the engine reduces size on the affected venue automatically. In this way, the read becomes an action rather than a footnote.
Routing decisions and venue choice
Routing variance measures the cost of one venue choice versus another, holding everything else equal. It depends on the engine’s routing policy and on the relative state of competing venues.
Therefore, an increase in routing variance often signals that a venue’s profile has changed. The engine may need to re-calibrate weights or pause a venue altogether. Inside slippage attribution, this component connects routing logic to measurable cost, which makes the policy testable rather than opinion-based.
In addition, routing variance is the component most affected by competition between venues. A venue that wins flow today may lose it tomorrow as participants shift. As such, the engine treats routing baselines as moving targets rather than fixed numbers.
Timing variance and slippage attribution
Timing variance captures the cost of executing later than intended. Even small delays can move the achievable price. As such, the component links the system’s latency profile directly to its slippage.
In practice, timing variance is the component most affected by infrastructure changes. A new release, a new data feed, or a new network route can each move it. For this reason, the engine watches timing variance closely after every meaningful infrastructure change.
Moreover, timing variance carries a useful diagnostic property. It tends to spike sharply rather than drift slowly. As such, a sudden change in this component is often the first sign that something concrete and recent has changed in the stack.
How Engineers Build a Slippage Attribution Framework
A slippage attribution framework is not a single metric, it is a pipeline. Data has to be captured at the right points, joined cleanly, and turned into per-fill component estimates. Therefore, engineering attribution is as much about data discipline as about modelling.
Building the slippage attribution baseline
Every slippage attribution framework needs a baseline for each component. The baseline is the expected behaviour of that component in normal conditions. As such, the engine compares each new fill against the baseline rather than against an arbitrary threshold.
Furthermore, the baseline is built from many fills, not a handful. A small sample produces noisy expectations and false alarms. In practice, the engine maintains rolling baselines per instrument, per venue, and per regime, so that comparisons stay honest.
In addition, baselines decay if they are not refreshed. Markets change, and a baseline calibrated months ago may already misrepresent today. Therefore, the engine refreshes baselines on a defined cadence, never letting an old reference quietly mislead new fills.
Logging fills with enough context
Attribution depends on the data captured at the moment of each fill. The engine logs the decision price, the indicative depth, the venue, the order type, the routing path, and the timestamps along the way. Without that context, no decomposition is possible.
For this reason, attribution forces a discipline on the rest of the system. A team that wants honest attribution must invest in honest logs. This connects directly to broader data trust in systematic trading, where the quality of the underlying record decides the quality of every downstream signal.
Moreover, logging gaps compound silently. A missing timestamp here, an incomplete depth snapshot there, and within weeks the attribution pipeline produces noise rather than signal. As such, the engine treats log quality as a first-class engineering concern, on par with the trading logic itself.
Attribution as a continuous pipeline
Slippage attribution only earns its place when it runs continuously, not occasionally. The engine computes component values for every fill, stores them, and updates the rolling baselines. Therefore, the pipeline is part of the system’s day-to-day infrastructure rather than a quarterly review.
Moreover, a continuous pipeline lets the engine spot small shifts early. A component creeping upward by ten percent over a week is the kind of signal a periodic review would miss. As such, continuous attribution is what turns small drift into early action.
Furthermore, the pipeline produces a written record that survives every team change. Engineers move on, but the attribution log stays. In this way, institutional memory becomes structural rather than personal.
Reading Slippage Attribution Across Regimes
A slippage attribution framework is most useful when it can compare regimes. Calm sessions and stressed sessions produce different baselines. The engine has to know which it is in before it interprets any component.
Calm regime slippage attribution
In calm regimes, every slippage attribution component stays close to its baseline. Market impact is small relative to depth. Liquidity drift is near zero. Routing and timing variance are stable. As such, calm is the cleanest measurement environment the engine has.
Furthermore, calm regimes are where the engine refreshes its baselines honestly. If a baseline is calibrated only during stress, it will misjudge normal conditions later. Therefore, the engine treats calm sessions as essential data, not as down-time.
In practice, calm conditions also surface small structural changes that stress would obscure. A quiet shift in venue behaviour stands out clearly when nothing else is moving. As such, calm regimes do double duty for the engine, refreshing the baseline and revealing early drift.
Reading stress regimes through attribution
Under stress, slippage attribution components all shift, but rarely in the same way. Market impact grows because depth thins. Liquidity drift jumps because the book changes during the fill. Timing variance widens because latency increases everywhere.
Reading those shifts together tells the engine which kind of stress is in play. A liquidity-driven stress looks different from a latency-driven one. In this way, attribution acts as a triage tool, helping the engine respond to the right cause rather than to the largest number.
Slippage Attribution and Venue Differences
Slippage attribution does not look the same across venues. Each market has its own depth profile, order types, and timing characteristics. Therefore, the components have to be re-calibrated for every venue rather than assumed to carry across.
ASX slippage attribution profile
On the ASX, slippage attribution is shaped by venue concentration and a heavy closing auction. Liquidity drift can rise sharply around the close. Market impact is larger relative to depth than in deeper markets. Routing variance, by contrast, is small because the order book is centralised.
As a result, the ASX attribution profile emphasises impact and liquidity drift more than routing. The engine knows this in advance and weights its baselines accordingly.
Furthermore, the ASX profile is most informative around session boundaries. The open and the close concentrate volume into short windows, and each component behaves differently inside those windows than in continuous trading. In this way, attribution baselines on the ASX must be time-of-day aware, not just regime aware.
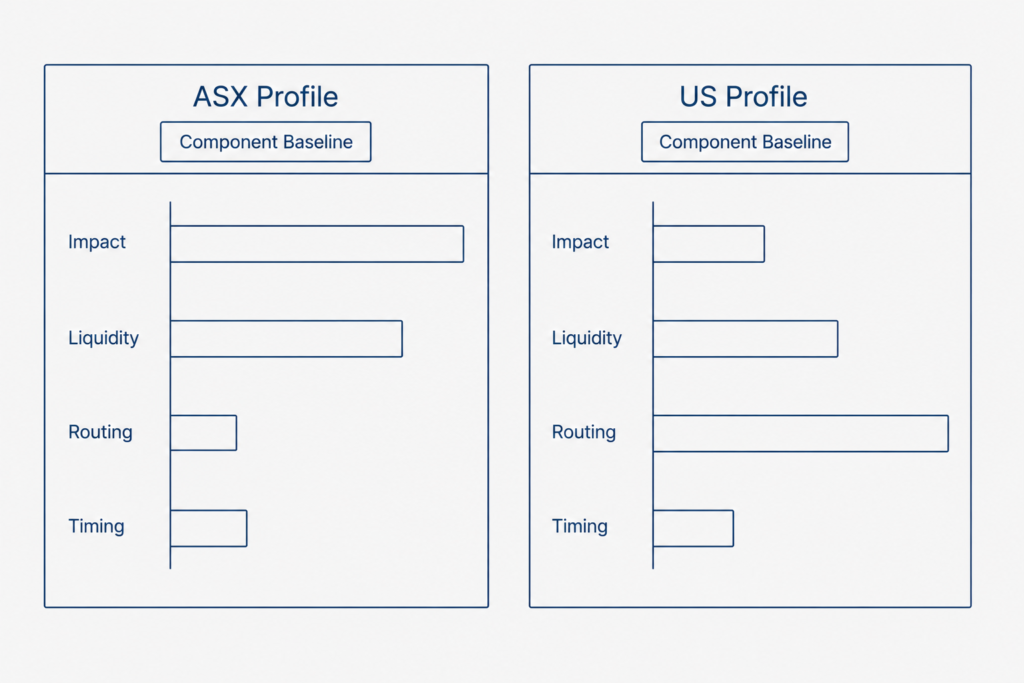
US slippage attribution profile
US large-cap venues run across a fragmented landscape. Routing variance becomes a much larger component, because order flow can split across many venues. Liquidity drift behaves differently again, because depth is composed across competing books.
Consequently, the US slippage attribution profile cannot be borrowed from the ASX. Instead, the engine re-measures each component on US data before it lets the framework drive any decision. The strategy stays the same. The attribution baselines do not.
In addition, US fragmentation makes individual venue attribution more important than the aggregate. A composite picture can hide which specific venue is changing. Therefore, the engine tracks each venue separately and only rolls the components up after the per-venue read is clear.
Slippage Attribution in Risk and Drawdown Policy
A slippage attribution framework only earns its place when it changes how the engine manages risk. A clean read with no consequence is just analytics. The engine has to act on the components, not just collect them.
Attribution as a halt trigger
A specific slippage attribution component crossing a defined threshold can trigger a halt or reduction. For example, persistent liquidity drift above baseline can pause a strategy on a venue. By contrast, a one-day spike in timing variance might trigger a smaller adjustment rather than a halt.
This decision logic connects directly to monitoring pipelines for behaviour drift, where attribution signals feed the same kind of pre-committed thresholds that govern other parts of the engine. As such, attribution becomes part of the engine’s risk vocabulary rather than a separate dashboard.
Moreover, the halt rules are defined before live pressure, never adjusted during it. The engine commits in advance to which component breach causes which response. In this way, attribution turns a noisy day into a documented adjustment, not a reactive judgement call.
Slippage attribution and sizing decisions
Attribution also informs how much size the engine commits. When a component widens against baseline, the engine can scale down on the affected venue or instrument. Furthermore, it can scale back up as the component returns to baseline, without overreacting to a single noisy day.
In this way, sizing follows attribution. The engine deploys more capital where components are clean and stable, and less where they drift. As a result, capacity follows evidence rather than ambition.
The Limits of Slippage Attribution
Slippage attribution is a powerful infrastructure property, but it has limits. A disciplined engine respects those limits rather than treating attribution as a complete answer.
When slippage attribution misleads
Slippage attribution can mislead when the data feeding it is wrong. A bad timestamp can inflate timing variance. An incomplete depth snapshot can distort liquidity drift. Furthermore, very low fill counts produce baselines that are easy to mistake for signal.
For this reason, the engine treats attribution as one input among several. It cross-checks components against fill counts, regime tags, and external data. As such, attribution earns trust by being verifiable, not by being precise.
Slippage attribution is not a forecast
Slippage attribution describes what has changed. It does not predict the next change. Moreover, a widening component is information about the current regime, not a guarantee about the next one.
For this reason, the engine treats attribution as a structural read, not a forecasting layer. It informs adjustments to sizing and halts. However, it never replaces filtration or decision logic upstream. Each layer has its own job, and attribution belongs in monitoring, not in entry rules.
Furthermore, a healthy team uses attribution to challenge its own assumptions, not to confirm them. If a component looks too clean for too long, that itself is information. As such, attribution earns its place when it surfaces uncomfortable signals as well as reassuring ones.
A slippage attribution framework turns a single complaint into a structured diagnosis. It separates market impact, liquidity drift, routing variance, and timing variance, then tracks each one against an honest baseline. By engineering the pipeline, re-calibrating per venue, and tying components to pre-committed risk responses, a systematic engine stays modellable, auditable, and repeatable under conditions that would otherwise hide their causes. In this way, slippage attribution supports the core Dovest principle. Structure comes first, and prediction never enters the design.
Continue Exploring Dovest Research
Explore more behavioural research from Dovest. The series builds a structure-first view of systematic trading, one framework at a time.
About the Author
This article reflects the research perspective of the Dovest team. Dovest designs systematic trading infrastructure with a behaviour-first philosophy. The focus stays on structure, filtration, and risk architecture that keep engine behaviour stable, explainable, and consistent across markets. Dovest writes from an engineering standpoint, not a forecasting one. Every framework here describes how disciplined systems reason, rather than what any market will do next.
Disclaimer
This article is for educational and informational purposes only. It does not constitute financial, investment, or trading advice. Dovest does not provide signals, forecasts, or guaranteed outcomes. Readers should not treat anything here as a recommendation to buy or sell any security. Furthermore, readers should consult a licensed professional before making any financial decision.








