Why Monitoring Pipeline Behaviour Drift Detection Comes Before System Failure
Systematic trading infrastructure relies on one assumption above all others: the engine will behave the same tomorrow as it does today. However, behaviour does not hold constant by itself. Monitoring pipeline behaviour drift detection exists precisely because engines change in subtle ways before they fail in obvious ones. The architecture that identifies this drift early gives operators something no post-trade review can offer: the ability to act before damage compounds.
Behaviour drift rarely announces itself. In practice, it accumulates slowly: holding periods extend by a fraction, position sizing edges outside its expected range, and exit timing shifts without a corresponding signal change. Consequently, the trading engine keeps producing output while its internal character quietly changes. A monitoring pipeline catches these shifts at the structural level, before they become visible in performance data.
This article examines the design logic behind a robust monitoring pipeline, what behaviour drift means inside a systematic framework, and how early warning architecture converts observation into governance. Furthermore, it explains why this infrastructure layer carries the same engineering weight as execution logic or risk controls.
The Purpose of a Monitoring Pipeline in Systematic Trading
A monitoring pipeline does not exist to measure returns. Instead, it exists to measure the engine itself. The distinction matters because performance metrics are lagging indicators. By the time a drawdown appears in a report, the underlying behaviour that caused it has already run its course. A monitoring pipeline for behaviour drift operates upstream of performance, tracking the structural variables that precede outcomes.
In this way, the pipeline reframes what oversight means in a systematic context. Oversight becomes an ongoing structural function, not a periodic review. The engine produces behaviour continuously, and the pipeline observes it continuously. As a result, the governance layer receives a living record of how the system operates, not a retrospective summary.
Monitoring Pipeline Infrastructure That Reads Behaviour
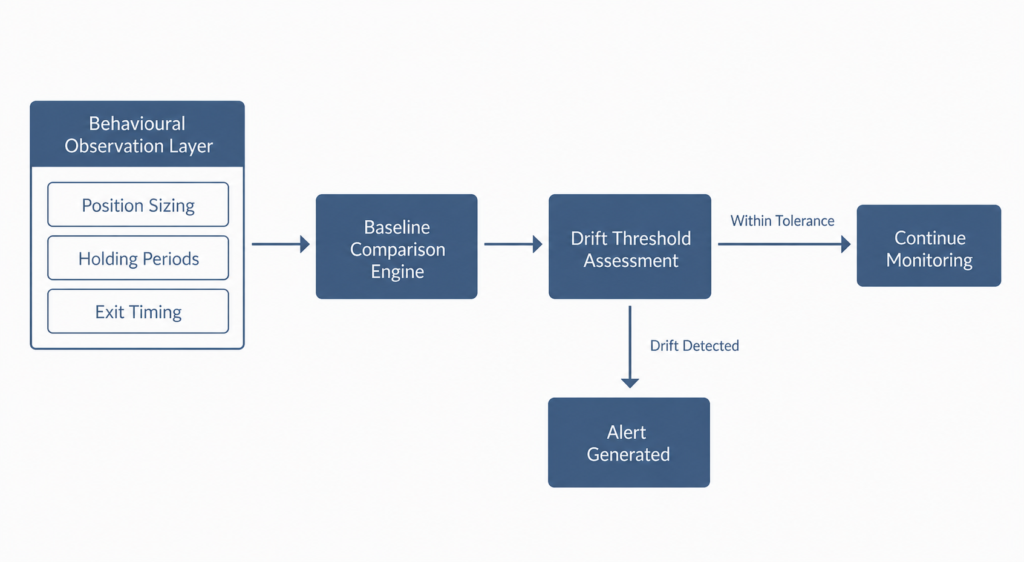
The monitoring pipeline observes holding period distributions, position sizing variance, entry timing relative to session structure, and exit logic consistency. Specifically, it does not evaluate whether trades were profitable. It evaluates whether each trade behaved in the way the system intended. This separation between outcome monitoring and behaviour monitoring represents a foundational architectural choice.
Systematic infrastructure built around behaviour monitoring gains an early warning signal that outcome-only systems cannot produce. Moreover, the pipeline converts these observations into structured alerts rather than simple notifications. An alert does not mean “something went wrong.” It means “something changed.” That distinction shapes how operators respond and, equally, how quickly they can respond.
Why Behaviour Comes Before Price in Pipeline Design
A monitoring pipeline that reads price data first inverts the priority hierarchy. Price reflects an outcome of behaviour, market structure, and liquidity dynamics combined. Therefore, a pipeline anchored to price tells operators what happened. A pipeline anchored to behaviour tells operators how the engine responded. The latter carries greater diagnostic value.
By design, a behaviour-first pipeline reports on three dimensions: consistency of decision-making logic, adherence to pre-committed constraints, and variance in output relative to expected distributions. These three dimensions form the observational backbone of any serious monitoring architecture. In addition, they give the governance layer a vocabulary for discussing system health that does not depend on short-term returns.
Behaviour Drift and Why It Precedes System Breakdown
Behaviour drift refers to the gradual divergence of an engine’s actions from its defined operating parameters. It does not require a flaw in core logic. In fact, drift often emerges from interactions between the engine and changing market conditions, data irregularities, or infrastructure latency shifts. For this reason, the monitoring pipeline must distinguish between drift caused by the engine itself and drift caused by the environment.
Both forms of drift carry risk. However, they require different responses. Engine-origin drift suggests a parameter review. Environment-origin drift suggests a regime-context analysis. A monitoring pipeline that cannot separate these two categories generates alerts that operators cannot act on with confidence.
Defining Behaviour Drift in a Systematic Context
Drift carries a specific meaning inside a systematic framework. It refers to a measurable change in a behavioural variable that falls outside the engine’s expected distribution. However, not all variance qualifies as drift. A single outlier session does not constitute drift. A consistent shift in a metric across multiple sessions does.
Consequently, a monitoring pipeline for behaviour drift must work with rolling windows, baseline distributions, and statistical thresholds rather than fixed rules. The architecture compares current behaviour against expected behaviour, then flags divergence only when it exceeds a pre-specified tolerance level. In practice, this means the pipeline produces fewer alerts than a rule-based system, but each alert carries significantly more diagnostic weight.
How Systems Drift Before They Break
Drift precedes breakdown in a consistent pattern. First, a behavioural metric moves outside its expected range. Next, the engine continues functioning without visible failure. Then, a second metric shifts. Over time, the compound effect of multiple simultaneous drifts creates the conditions for a performance degradation event or a halt trigger.
Because each individual drift appears tolerable in isolation, post-trade analysis rarely catches it in time. The monitoring pipeline catches it in sequence, not in retrospect. Furthermore, the pipeline retains a historical record of all drift events, which supports post-event analysis and governance documentation. In this way, the architecture serves both detection and accountability functions simultaneously.
Structural Components of a Monitoring Pipeline
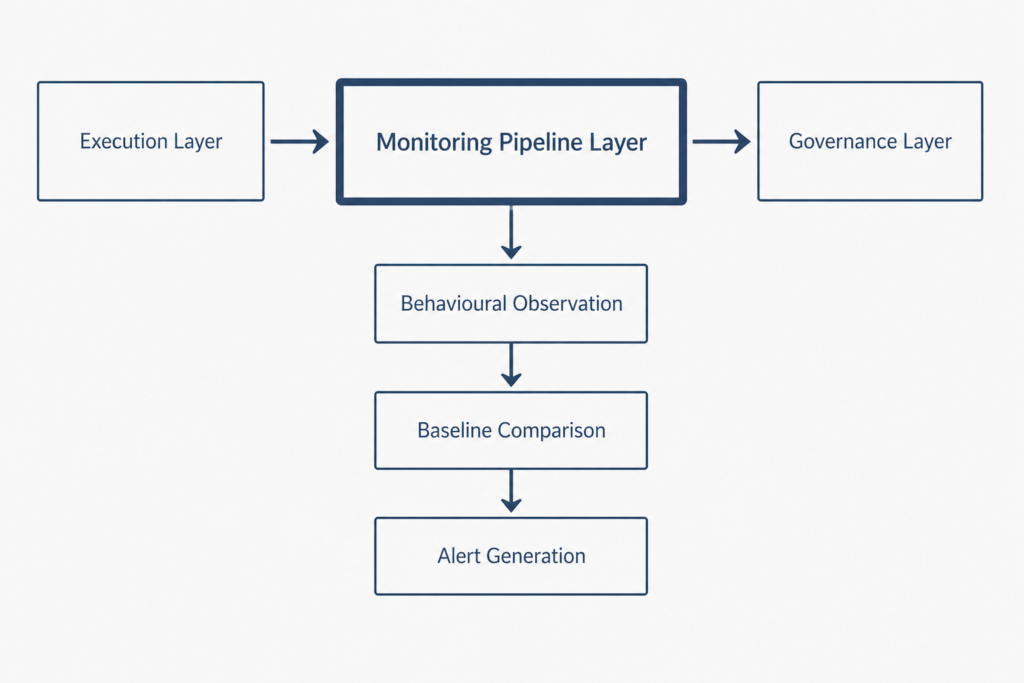
A robust monitoring pipeline for behaviour drift requires more than observation capability. It requires a defined architecture: what data enters the pipeline, how the comparison layer processes that data, and at what point the system generates an actionable signal. Each decision in this architectural chain affects the quality of the alert output.
Organisations that treat monitoring as an afterthought typically bolt a reporting layer onto an existing execution system. This approach produces noise rather than signal. By contrast, purpose-built monitoring pipeline architecture treats each layer as a distinct engineering problem with its own design criteria and failure modes.
The Three Layers of Pipeline Monitoring
Every effective monitoring pipeline operates across three structural layers. The first layer is the observation layer, which collects raw behavioural data from every trade and session. The second layer is the comparison layer, which measures current behaviour against established baseline distributions. The third layer is the alert layer, which converts threshold breaches into structured notifications.
Each layer serves a distinct function. Furthermore, the design prevents any single layer from interpreting results outside its scope. The observation layer does not judge. The comparison layer does not alert. The alert layer does not diagnose. In this way, each layer maintains clean boundaries, which reduces both false positives and missed detections. Additionally, this separation makes each layer independently auditable, which matters for governance documentation.
Alert Architecture in a Monitoring Pipeline
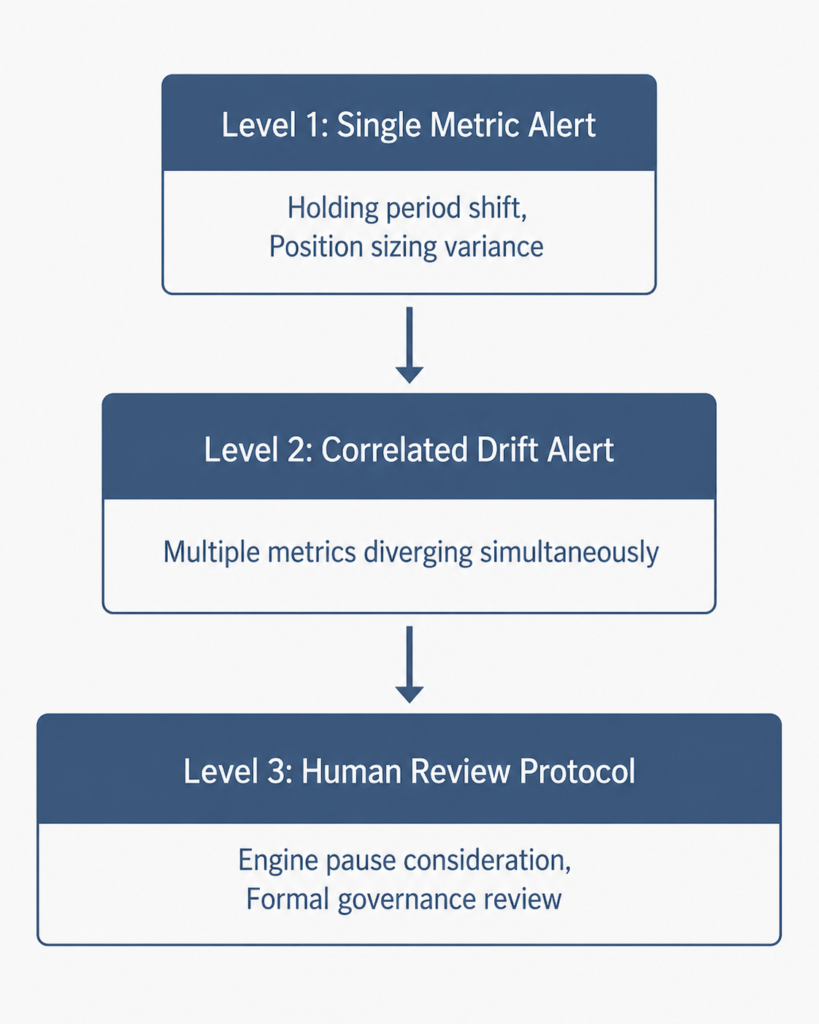
Alert architecture within the monitoring pipeline follows a tiered logic. Level-one alerts flag a single metric outside its expected range. Level-two alerts flag two or more correlated metrics shifting simultaneously. Level-three alerts trigger a human review protocol, which may include a temporary engine pause under defined halt conditions.
By contrast, a monitoring pipeline without tiered alerts generates noise at the same volume as signal. The result is alert fatigue, which renders the pipeline functionally useless regardless of its technical sophistication. Tiered architecture solves this problem structurally by ensuring the alert layer communicates proportionally to the severity of drift detected. As a result, operators develop confidence in the signal rather than dismissing it by default.
Thresholds in Monitoring Pipeline Architecture
Thresholds represent the governance interface of the monitoring pipeline. They define the boundary between acceptable variance and actionable drift. In practice, thresholds express in probabilistic terms: if a metric falls outside a two-standard-deviation band for three consecutive sessions, the pipeline logs a level-two alert.
Equally important, thresholds do not change without a formal review process. The monitoring pipeline therefore encodes governance logic directly into its structure. No informal override shifts a threshold mid-session. No ad-hoc adjustment responds to a single uncomfortable trade. Consequently, the threshold architecture preserves the pipeline’s integrity as an objective measurement system rather than a subjective one.
Early Warning Signals in a Monitoring Pipeline
The value of a monitoring pipeline lies in its ability to surface signals before outcomes deteriorate. However, not every behavioural shift qualifies as an early warning. The pipeline must distinguish between signals that indicate genuine drift and signals that reflect legitimate regime variation. This filtering function sits at the core of pipeline design quality.
An early warning architecture that cannot make this distinction will either overwhelm operators with false alerts or fail to surface genuine drift before it compounds. Neither outcome supports effective governance.
Behaviour Drift Indicators Worth Measuring
The most reliable behaviour drift indicators include holding period distribution shifts relative to session type, position sizing variance outside the expected range for the prevailing volatility regime, and entry timing drift relative to the session’s structural phase. Additionally, exit logic consistency metrics track whether the engine closes positions according to its pre-committed exit rules or with measurable deviation.
Each indicator operates independently within the pipeline. Moreover, the pipeline tracks correlations between indicators. When two or more indicators shift simultaneously, the early warning value increases significantly. Correlated drift signals carry diagnostic weight that single-indicator alerts cannot match. In particular, simultaneous shifts in holding period and exit timing suggest a structural change rather than a statistical outlier.
Structural Gaps in Early Warning Coverage
No monitoring pipeline catches every form of drift. Specifically, pipelines built around historical baseline distributions will miss drift that occurs in genuinely novel market conditions. A regime that falls outside the engine’s historical environment can produce behaviour shifts that look normal relative to existing distributions but represent genuine structural misalignment.
Therefore, monitoring pipeline behaviour drift detection functions as one layer in a broader governance framework. It does not replace regime-context analysis, data integrity checks, or human oversight protocols. Nevertheless, it provides the earliest structural signal of any layer in the system, which gives governance processes the maximum possible lead time.
Reading Context, Not Just Data
A monitoring pipeline that ignores market context generates alerts that confuse operators rather than inform them. Specifically, holding period extensions are normal in low-liquidity regimes. Position sizing variance is expected during elevated volatility sessions. A pipeline that treats these regime-specific variations as behaviour drift produces a high false-positive rate and erodes operator confidence in its outputs.
The solution is not to reduce sensitivity. Instead, it is to condition each behavioural metric on the current market environment. Context-aware monitoring maintains sensitivity to genuine drift while filtering out regime-driven variance that the engine produces by design.
Regime Awareness in Monitoring Pipeline Filters
Regime-aware monitoring pipeline filters address the context problem by applying different tolerance bands for different regime categories. In practice, a volatility-expansion session triggers a wider holding period tolerance. A low-volume session triggers adjusted position sizing thresholds. The pipeline does not reduce its sensitivity; it recalibrates its reference point.
Understanding how systematic frameworks manage data integrity within their pipelines connects directly to data trust in systematic trading, where feed quality and normalisation logic directly affect what the monitoring layer receives. A monitoring pipeline with unreliable input data produces unreliable alerts regardless of the sophistication of its threshold architecture. In this way, data trust and monitoring pipeline design form an interconnected governance chain.
Cross-Layer Comparison for Drift Detection
Cross-layer comparison enriches the monitoring pipeline by examining how individual metrics relate to one another across time. For instance, if holding periods extend while exit timing also shifts, the pipeline records a cross-layer divergence. By contrast, if holding periods extend while exit timing remains stable, the signal carries different diagnostic implications.
In this way, cross-layer comparison gives the monitoring pipeline a richer view of engine behaviour than any single metric can provide. Consequently, the architecture moves from raw observation toward structured inference without requiring human judgment at every step. This capability represents a significant advance over single-metric monitoring systems, which treat each alert in isolation.
Human Oversight and Structural Discipline
The monitoring pipeline does not replace human judgment. Instead, it produces structured information that human oversight can act on within defined constraints. This distinction matters because a pipeline that automates all decisions removes the accountability layer that institutional governance requires.
Human oversight in a systematic framework does not mean discretionary interference. It means a defined review process that activates at specified alert thresholds and follows a pre-committed decision tree. The monitoring pipeline supports this process by providing structured inputs, not open-ended recommendations.
When Monitoring Pipeline Output Triggers Review
The monitoring pipeline triggers a formal human review when level-three alerts fire. At this stage, the operator receives a structured report covering which metrics drifted, by how much, over what time period, and whether cross-layer correlations were present. The review protocol then follows a defined decision tree: continue, adjust parameters within pre-committed bounds, or halt.
The system integrity framework governs what each of these options requires in practice. A clear understanding of system integrity in systematic trading explains why the decision tree must remain pre-committed rather than discretionary. Discretionary decisions at the review stage introduce the precise instability the monitoring pipeline exists to prevent. In addition, undocumented decisions create governance gaps that undermine auditability.
Override Architecture and Structural Boundaries
Override capability does not belong in monitoring pipeline architecture. The pipeline’s purpose is to observe, compare, and alert. It does not make recommendations beyond its defined tier logic. Additionally, it does not grant permission for unscheduled changes to engine parameters.
Those decisions belong in a separate governance process with its own documentation and authorisation requirements. By maintaining this separation, the monitoring pipeline preserves its function as an objective observer. Once a pipeline begins interpreting its own alerts and recommending responses, its observational integrity collapses. Furthermore, an overrideable monitoring system provides weaker governance assurances to any external oversight body.
Why Monitoring Matters as Infrastructure
Organisations often treat monitoring as a reporting function rather than a structural one. This framing underestimates the role a monitoring pipeline plays in long-run system stability. In practice, a monitoring pipeline for behaviour drift represents infrastructure in the same sense as execution logic or risk architecture: it runs continuously, generates structured outputs, and feeds directly into governance processes.
The difference between a monitoring pipeline and a reporting tool is the difference between detection and documentation. Reporting describes what happened. A monitoring pipeline determines whether what happened falls within the system’s defined operating envelope, and it does so in real time.
Long-Run Integrity Through Behaviour Drift Monitoring
Long-run system integrity depends on the monitoring pipeline operating at full fidelity across all market conditions. In particular, the periods when monitoring matters most are precisely the periods when the pipeline faces the greatest stress: high-volatility regimes, data feed disruptions, and low-liquidity sessions. These are the conditions under which behaviour drift is most likely to occur and most likely to go undetected without robust pipeline architecture.
For this reason, monitoring pipeline design receives the same engineering attention as any other system layer. Redundancy, failover logic, and alert delivery mechanisms require explicit design decisions. A monitoring pipeline that fails silently during a stress event provides no protection at the moment it matters most. Equally, a pipeline that degrades gradually under stress produces progressively unreliable outputs without signalling its own deterioration.
Conclusion: Building Systems That Watch Themselves
Systematic trading infrastructure requires self-awareness at the structural level. A monitoring pipeline for behaviour drift detection provides exactly that: a continuous, objective view of how the engine behaves relative to its own defined parameters. In practice, this shifts the governance model from reactive to proactive, from observation after the fact to detection before the breakdown.
Early warning architecture does not prevent all failures. However, it shrinks the window between drift onset and detection. That window is the interval where damage accumulates, where small behavioural changes compound into structural misalignment. Consequently, a well-designed monitoring pipeline represents one of the most important governance investments a systematic trading infrastructure can make.
The engine does not know when it begins to drift. The monitoring pipeline does.
Explore more behavioural research from Dovest and continue learning about the infrastructure frameworks that keep systematic trading engines stable, explainable, and accountable.
Author : This article reflects the institutional research and infrastructure philosophy of the Dovest systematic trading team. Dovest designs behaviour-first trading frameworks focused on structure, filtration, and governance that makes performance repeatable, not fragile.
Disclaimer: This content reflects institutional research and infrastructure design philosophy. Nothing in this article constitutes financial advice, investment recommendations, or trading signals. All frameworks described represent engineering-grade research, not validated performance claims.