
Data Trust: Preventing Future Leakage in Systematic Trading
Most discussions about data leakage focus on detection. Teams build logs, audits, validations, reconciliations—mechanisms designed to discover errors after they occur. However, data trust systematic trading approaches this differently. In live systems, data trust represents an architectural boundary problem rather than a monitoring challenge that teams must engineer upstream rather than detect downstream.
The conventional question asks how teams can detect leakage faster. In contrast, the architectural question asks how designers can build systems so future leakage cannot occur—even as the system evolves, even as new features arrive, even as assumptions change. This distinction separates systems that drift from systems that hold.
This article explains why teams must engineer data trust into infrastructure, how leakage actually emerges in production environments, and what architectural principles prevent contamination without relying on discipline, audits, or retroactive fixes.
Why Clean Data Differs from Data Trust Systematic Trading
Clean Data Represents an Outcome; Data Trust Defines a Property
A dataset can appear clean—displaying no missing values, no obvious errors, no formatting inconsistencies—yet remain fundamentally untrustworthy. This distinction matters because teams often conflate data quality with data trust, treating them as equivalent when they actually operate at entirely different architectural levels.
Data trust transcends accuracy at a single point in time. Instead, it establishes causal integrity across time. The critical questions focus not on whether the data appears correct now, but whether you can prove why this data exists, guarantee what it did not know at the moment teams created it, and prevent future states from contaminating past decisions.
If the answer to any of these questions relies on “we check later” or “we validate afterward,” the system already carries fragility. Validation assumes failure will occur. In contrast, data trust systematic trading removes the possibility of certain failures entirely.
Data Trust Systematic Trading Demands Structural Proof
Traditional data quality frameworks focus on observable properties: completeness, consistency, accuracy, timeliness. While these properties remain necessary, they prove insufficient. Data trust requires something deeper—structural proof that future information could not have contaminated the data at the moment teams created it.
This challenge transcends testing. You cannot test your way to trust. Rather, you can only architect your way there.
How Future Leakage Emerges in Data Trust Systems
Beyond Obvious Look-Ahead Bias in Data Trust
Future leakage in research or backtesting often appears obvious. Using tomorrow’s close to predict today’s entry becomes trivially detectable. However, in production environments, leakage manifests subtly, structurally, and cumulatively. It emerges not from coding errors but from architectural decisions that seemed reasonable at the time.
The most dangerous leakage patterns develop slowly, appearing only after months of operation when behavioral drift becomes undeniable but its cause remains obscure.
Temporal Boundary Erosion in Data Trust Systematic Trading
Live systems evolve continuously. New signals arrive. Data feeds expand. Execution logic improves. Without strict temporal boundaries enforced at the architectural level, future information leaks backward through three primary mechanisms.
First, shared feature stores that serve both research and production create bidirectional contamination pathways. When a feature computation improves, the “better” version often propagates to historical data under the assumption that improvement always benefits outcomes. Yet improvement in understanding differs from improvement in what teams could know at decision time.
Second, recomputed aggregates silently rewrite history. Teams recalculate rolling windows, volatility estimates, correlation matrices—all with hindsight that incorporates data points that did not exist when teams made the original decision. The system appears stable because the logic remains consistent. However, the behavior shifts because the inputs have changed.
Third, replayed datasets used for consistency checks or model retraining inadvertently introduce future knowledge. The replay applies current processing logic to historical raw data, producing features that could not have existed in their original form. Consequently, data trust systematic trading systems must prevent this category of contamination architecturally.
Role Confusion Inside Data Trust Pipelines
When the same data object serves multiple purposes—research exploration, simulation validation, live decision-making, performance monitoring—trust collapses. A dataset cannot simultaneously serve exploratory and authoritative roles without contaminating one of those functions.
Exploratory data benefits from recomputation, refinement, and hindsight. In contrast, authoritative data must remain frozen, immutable, and historically accurate. Conflating these roles represents one of the most common sources of subtle leakage in production systems.
Silent Recomputation Rewrites Data Trust History
Rebuilding features with improved logic seems harmless. The new logic appears better. The calculations achieve greater accuracy. The methodology gains sophistication. Nevertheless, unless historical states freeze at the moment of their use, recomputation rewrites what the system actually faced in real time.
The danger emerges not because the new calculation produces wrong results. Rather, the danger manifests because the system starts answering a different question than the one it actually confronted during live operation. Behavioral integrity dissolves even as technical quality appears to improve.
Data Trust Represents a Forward-Looking Architectural Problem
The Wrong Question vs The Right Question in Data Trust
Most teams ask: “Does this data appear correct right now?” That question focuses on current state validation. In contrast, data trust systematic trading asks: “Can this data ever become incorrect in the future?” That question focuses on structural prevention.
This shift matters because once a live system exists, the greatest risk transcends current error. Teams usually detect current errors through monitoring and reconciliation. Instead, the greatest risk emerges from future contamination of past decisions—corruption that makes historical behavior unreproducible and system evolution behaviorally invalid.
Why Future Contamination Dominates Data Trust Risk
In production environments, data rarely breaks loudly. Rather, it drifts subtly. A feature that worked correctly for six months suddenly starts behaving differently not because the code changed but because upstream “improvements” retroactively modified the data it depends on.
Performance decays slowly. Behavior changes in ways that seem plausible individually but accumulate into systematic drift. By the time the problem becomes visible, months of decisions have relied on contaminated foundations. Trust has already eroded; teams simply discover it late.
The Architectural Principle: Data Trust Enforces Rather Than Verifies
Verification Assumes Failure Will Occur in Data Trust
Audits, checks, and validations all operate on the assumption that something can go wrong and the goal involves catching it when it does. This mindset guarantees two outcomes: leakage will occur, and teams will only discover it after behavior has already shifted.
Verification operates reactively. It responds to contamination after it materializes. In live systematic trading infrastructure, reactive discovery means the system has already made decisions using untrustworthy data. The damage has occurred; verification simply quantifies it.
Enforcement in Data Trust Systematic Trading
Teams must enforce data trust through structural separation, one-way data flows, and irreversible boundaries. If a system cannot access future information, it does not need trust to avoid using it. The architectural constraint removes the possibility.
This approach transcends discipline or process rigor. Those elements depend on humans and therefore prove fragile under pressure. Instead, enforcement makes certain classes of contamination structurally impossible. The system cannot leak what it cannot reach.
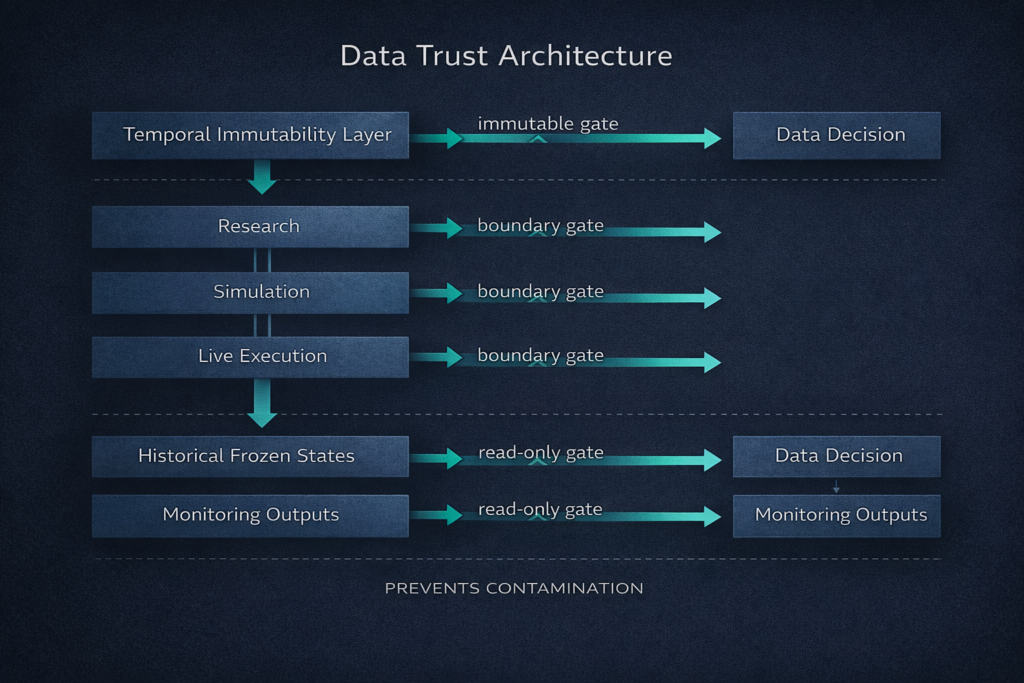
The Data Trust Systematic Trading Stack: Conceptual Layers
Layer 1: Temporal Immutability in Data Trust
Once teams consume data for a decision in a live system, they must freeze it. Immutably. Permanently. Even if better processing logic emerges later, even if the methodology improves, even if the calculation was suboptimal. Teams preserve historical truth not because it was perfect but because it was real.
This principle feels counterintuitive to research teams accustomed to iterative improvement. However, in production systems, behavioral integrity requires that the system always knows what it knew then, not what it knows now. Improvement applies only forward in time. History remains frozen.
Temporal immutability transcends versioning for rollback. Rather, it guarantees that teams can reproduce every decision made in real-time using only the information available at that moment. This guarantee forms the foundation of data trust systematic trading infrastructure.
Layer 2: Functional Separation in Data Trust Systems
Research data, simulation data, and live decision data must never share write paths. They may originate from the same raw source—market data feeds, execution logs, position states. Yet once they diverge into their respective roles, they never converge downstream.
Teams can recompute, refine, and enrich research data with hindsight. Simulation data can incorporate alternative scenarios and counterfactual analysis. Meanwhile, live decision data remains frozen at the moment of use, immutable and historically accurate.
This separation operates architecturally, not procedurally. Teams cannot maintain it through discipline or careful process management. Instead, infrastructure must enforce it by making cross-contamination impossible.
Layer 3: Directional Permission Through Data Trust
Live systems can read historical frozen states. However, they cannot write to them. Monitoring systems can observe live outputs. Nevertheless, they cannot influence decisions. This directional flow creates a trust boundary that prevents future information from flowing backward.
The permission model operates simply: data flows forward in time, never backward. Observations flow outward from decision systems, never inward. These constraints represent not policy recommendations but architectural invariants enforced at the infrastructure level.
Preventing Leakage During System Evolution Through Data Trust
Evolution Breaks Most Data Trust Systems
Teams add new features. Market conditions change. Assumptions evolve. Execution logic improves. Without enforced trust boundaries, evolution retroactively invalidates historical behavior. The system becomes impossible to reason about because teams cannot reproduce what it did yesterday with today’s codebase.
This concern transcends theory. Most production trading systems experience behavioral drift that teams attribute to “market regime change” when contamination introduced during routine system improvements actually causes the drift.
The Architecture-Level Rule for Data Trust Systematic Trading
No system component may improve historical understanding. Improvement applies only forward in time. This rule remains absolute and non-negotiable.
When new processing logic emerges, it applies to new data from the moment of deployment forward. Historical data processed under the old logic remains frozen in its original form. The system maintains a clear temporal boundary: before this date, we knew X; after this date, we knew X + Y.
This rule feels constraining. Research teams want to apply better methodology to historical data. They want to backfill improved features. They want consistency across time. However, consistency across time destroys behavioral reproducibility, which destroys trust.
Why Monitoring Cannot Solve Data Trust
Monitoring Answers the Wrong Question About Data Trust
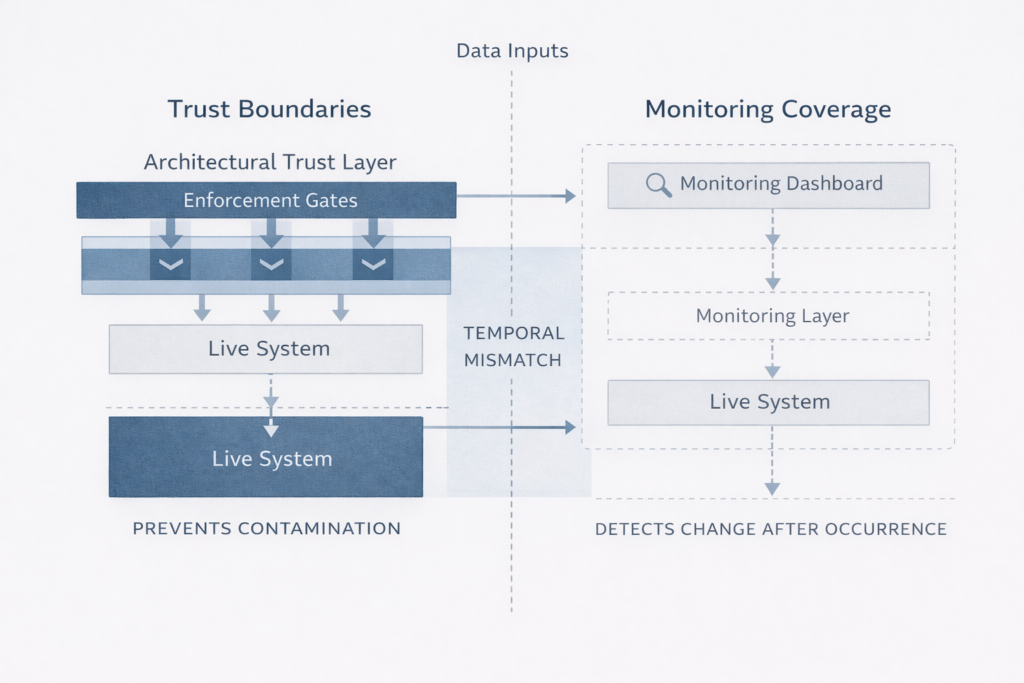
Monitoring systems answer: “Did something change?” In contrast, data trust asks: “Could something have changed without us knowing?” If the answer proves yes, monitoring remains insufficient regardless of alert sophistication.
The difference operates fundamentally. Monitoring operates after the fact. It detects changes in system behavior or data distribution and raises alerts. Yet if the contamination appears subtle—a slowly shifting feature distribution, a gradually eroding correlation, a feature that drifts rather than breaks—monitoring may never trigger.
Observation vs Authority in Data Trust Systematic Trading
Data trust systematic trading treats monitoring as observational, never authoritative. Monitoring provides visibility into system state. However, it does not enforce trust boundaries. Authority lies in architecture, not dashboards.
This separation matters because teams often conflate the two. Sophisticated monitoring creates confidence that teams will detect problems. Yet detection differs from prevention. By the time monitoring alerts, contamination has already occurred and decisions have already relied on untrustworthy foundations.
Data Trust and Behavioural Integrity
Behavioural Degradation Precedes Performance Issues in Data Trust
In live systematic trading systems, behavioural degradation often appears well before any detectable performance problem. Why? Because leakage subtly alters signal sensitivity, execution timing, and risk response in ways that remain statistically plausible while fundamentally changing how the system behaves.
The system still “works” in the sense that it generates decisions, executes trades, and produces outcomes. Nevertheless, it no longer behaves as designed. The original behavioral assumptions—the principles that guided architecture, the constraints that defined operation—have suffered violations from contamination that monitoring cannot detect.
Data Trust Systematic Trading Preserves Design Intent
Data trust systematic trading preserves behavioral integrity by ensuring the system always reacts to the same class of information, regardless of how much the environment or infrastructure evolves. Teams can add new features. Processing logic can improve. However, historical decisions remain reproducible using only the information available at the moment teams made them.
This preservation enables systematic infrastructure to scale over time. Without it, every improvement introduces the risk of invalidating past behavior, making it impossible to distinguish between environmental change and self-inflicted contamination.
Relationship to Filtration Logic in Data Trust
Complementary Architectural Layers in Data Trust Systems
Filtration logic answers: “Should this system act now based on structural validity?” Meanwhile, data trust answers: “Does the information we are acting on maintain temporal validity?” Both prove necessary; neither proves sufficient alone.
Filtration evaluates whether market structure, volatility regime, and execution conditions permit behavioral expression. In parallel, data trust ensures that the features and signals used to make that evaluation have not suffered contamination by future information. Without data trust, filtration gates become unreliable because the inputs to permission logic have lost temporal integrity.
Why Data Trust Systematic Trading Supports Everything Downstream
Data trust appears after filtration logic in systematic infrastructure roadmaps, but it supports everything built on top of it. Signal generation, regime classification, execution permission, risk constraint—all depend on trustworthy inputs. If those inputs have suffered contamination by future leakage, every downstream decision becomes suspect.
This explains why teams cannot add data trust as an afterthought or bolt it on as a validation layer. Rather, it must operate foundationally, built into the infrastructure before behavioral logic layers on top.
Institutional Perspective on Process Integrity
Institutional research consistently emphasizes that process integrity, not model sophistication, determines long-term system reliability. The Bank for International Settlements has highlighted that structural weaknesses—fragmentation, opacity, temporal inconsistency—dominate systemic breakdown risk far more than signal failure or parameter miscalibration.
Similarly, the CFA Institute frames governance, data lineage, and temporal validity as prerequisites for reliable decision systems. These represent not compliance overlays or best-practice recommendations. Rather, they constitute foundational requirements for systems that must operate continuously under evolving conditions.
Data trust systematic trading operationalizes these insights at the architectural level rather than treating them as policy frameworks teams must apply manually.
What Data Trust Systematic Trading Is Not
Common Misconceptions About Data Trust
To clarify precisely what data trust systematic trading requires, understanding what it is not proves important. Data trust does not mean better data cleaning. Cleaning improves quality at a point in time. In contrast, trust ensures validity across time.
It does not mean more validation checks. Validation detects problems. Conversely, trust prevents them. It does not mean stronger governance committees. Governance establishes accountability. However, trust removes the possibility of certain failures through structural constraint.
It does not mean stricter access permissions. Permissions control who can see data. In contrast, trust controls whether future information can contaminate data.
These distinctions matter because teams often attempt to solve trust problems with quality, validation, or governance solutions. Those tools address different concerns. They do not establish temporal integrity.
The Cost of Getting Data Trust Wrong
Systems that fail at data trust do not fail loudly or immediately. Instead, they drift. Performance decays slowly enough that attribution becomes ambiguous. Behavior changes subtly enough that each individual shift seems explainable. Paradoxically, confidence increases as integrity decreases because monitoring shows no obvious breaks.
By the time failure becomes undeniable, the system has already transformed into something fundamentally different from what designers intended. Months or years of decisions have relied on contaminated foundations. Historical behavior no longer proves reproducible. Teams cannot trust the system because they cannot verify its past.
Conclusion: Data Trust Represents Design, Not Earning
Live systematic trading systems do not become trustworthy through discipline, audits, or vigilance. Rather, they become trustworthy because certain things prove architecturally impossible. Certain paths do not exist. Certain knowledge cannot flow backward.
Data trust systematic trading represents not a maintenance task or operational discipline. Instead, it constitutes a design decision made once and defended forever. The infrastructure either prevents future leakage structurally, or it remains vulnerable to contamination regardless of team diligence.
Preventing future leakage means building systems where temporal boundaries receive enforcement, not verification. Where functional separation operates structurally, not procedurally. Where directional permission removes the possibility of contamination rather than detecting it after it occurs.
That defines what data trust means in production systematic trading infrastructure.
Continue Learning About Systematic Trading Infrastructure
Explore related insights on behaviour-first trading frameworks to understand how structural discipline protects long-term system integrity across all architectural layers.
About the Author
Dovest Research Team
The Dovest Research Team develops institutional-grade frameworks for systematic trading infrastructure, focusing on behaviour-first architecture, structural validity, and data integrity. All content reflects foundational research and methodological discipline rather than performance marketing or signal provision.
Expertise: Systematic trading architecture, data lineage, temporal integrity, behavioral consistency frameworks
Approach: Engineering-grade reasoning applied to trading infrastructure design, emphasizing what systems should prevent architecturally before considering what they might detect operationally.
This article reflects research and methodology. Dovest does not provide trading signals, performance predictions, or guarantee any specific outcomes. All systematic trading involves substantial risk.




